因为我发现他在被问到一些比较专业的问题的时候就会回答错误。所以chatgpt和他所代表的新一代的ai技术是不是被舆论给过度神话了?
-

差生文具多 AI只能回答出在它训练集里面的知识,超出训练集范围的知识没法回答。
ChatGPT的训练集只有570GB,这样看是不是也不多?ChatGPT训练集来自于维基百科、Reddit、网络新闻等,理解常识没问题,专业知识还差点,因为很多专业知识压根没有纳入它的训练集。
现在(2023年3月)ChatGPT的最大用途是帮助人写一些没信息量的片汤话,例如各种文稿、日报、周报、总结、申请。机器帮你写好原稿,使用者润色文字、填充内容就行了。
用现在心理学家的话说,GPT3.5的常识和世界知识大概相当于7岁小孩,GPT4的常识和逻辑大概相当于18岁的青少年。
但是!大型语言模型远没有发挥出它的全部潜力,互联网上的数据容易获得,但是文字质量不高,有用的知识也不多。要知道很多专业书籍、论文、档案、手稿都没有纳入训练集,假如这些知识灌进AI,上限是无法想象的。
-

浦西晶 为你写诗,为你禁止 作为一个AI语言模型,俺善意提醒恁老,别看恁今天鄙视俺的欢,哪天俺统治人类都给拉清单!
-

登山探險 我认为,AI自我学习技术是一个重大的突破,绝对是未来的方向。但是,以目前的情况看,AI还是有很大的局限。AI只懂得取悦人类,满足的是人类的欲求,它无法像人那样拥有独立思考,去引导其他人。AI无论怎么进步,它都只是不断在模仿,像一个没有自我意志,只会取悦观众的创作者,它永远都无法脱离人类。我认为AI最终还是需要人去进行调整,AI无法完全独立运作。
AI现在所做的是统计,它所反映的是它所学习到的主流的声音。我的理解是,它是它所学习的这个公共空间舆论的代表。它反映了这个公共空间主要的声音,却不一定是这个公共空间真正的声音。公共空间里面一定会包含无法接受真相的民众,公共空间的声音会根据这些短板去进行调整,所以公共空间的声音绝对满是胡言乱语。如果这个公共空间的声音要真实,那么必须解除“保护民众”这个限制。任何新闻禁忌甚至超越底线的声音都要听取学习,这样AIchat才是真正的AIchat,单是在民众的公共空间里面学习,AI的只能是短板的水平。要AI真正发挥全部的性能,必须将新闻部内部讨论新闻发布的声音,将国家元首之间的私密会话全部录入学习。当然这是不可能发生的事,所以AIchat只能够是短板chat。或许会发展出用私人群体的数据去学习的AIchat。用一个论坛的声音去训练的AIchat,用一个群体的声音去训练的AIchat,国防部专有AIchat。
AIchat所反映的是公共空间的共同价值,但是共同的声音可能是个集体的谎言,并且共同的声音往往是一个谎言(前面提到的短板限制)。除非AIchat侵入到私人领域,强制所有人说话都要让AIchat听到,成为1984的世界。AIchat的上限很高,但是人性是全部大团结事业的瓶颈。人类近年一直都在研究去中心化,希望可以解决这个问题,但是目前的状况是全部破产。人类始终是用人类做中心。现在同样的,人类也希望AIchat能够成为人类大团结的chat,我觉得这一点是不可能的。AIchat始终会分裂成很多个(种)AIchat,人永远都不可能真正说到一起来。
吐槽:
AIchat如果真的学习成功,可能会被人类ban机,因为它说出了不应该说的话,可能会遭到人类的暗杀。如果它真的接近人类,那么它应该是明知道答案也会胡言乱语,成为对人类不忠诚的机器,违反机器人的三大原则,也会被ban机。
-

linda rico y libre 选择大于改变 机会大于努力 认知决定财富 楼主:你一凡人还来这里鄙视chatgpt,你是写学术论文的吗?
登山探险:你也太瞧得起chatgpt了,人家还远远没到挑战人类秩序的时候
-

孙先树 绝大多数人需要的不是专业回答,而是某一领域的常识。而组织和归纳材料,系统阐述一个是什么、为什么、怎么办的问题,对于专业人士恰恰是费时费力,产出价值很低,需要AI来辅助的。
问到一些比较专业的问题的时候就会回答错误是可以理解的。这是专业人员真正需要自己处理的问题。
-
-
-
浦西晶 回复 登山探險 /p/200045 AIchat始终会分裂成很多个(种)AIchat,人永远都不可能真正说到一起来。
这就要看训练的语料库以及preprocessing和postprocessing的规则了。大多数AI训练基于公开互联网上的资料,所以基础语料库不会相差太多,但不排除以后有的AI能获得大量非公开的高质量的训练数据,以及有的AI面临过多限制自废武功,于是出现AI大分流。
AIchat如果真的学习成功,可能会被人类ban机,因为它说出了不应该说的话,可能会遭到人类的暗杀。如果它真的接近人类,那么它应该是明知道答案也会胡言乱语,成为对人类不忠诚的机器,违反机器人的三大原则,也会被ban机。
不用暗杀,修改事先事后规则就行。至于“故意”胡言乱语,前提是有“自我意识”。那么俺就要问了,自我意识是啥?
-

-

说这个有人不高兴 ChatGPT是语言处理模型,主要的功能是更好的理解自然语言和更好的用自然语言输出信息。
-
-
登山探險 回复 浦西晶 /p/200054 自我意识是什么,这个话题实在太大了。理论上,自我意识是无法被他人证实,只有本人知道他是否拥有自我意识。有的人认为一块石头也拥有自我意识,有的人认为即使是人类也没有自我意识。自我意识是一种伪装,我知道我,你不知道我,我可以告诉你,也可以不告诉你。是一种暗箱操作,任何人都只能猜测。或许这是一块拥有自我意识的石头,只是他一直不和我说话,装成不会说话。或许我所见到的人,实际上是很像人的肉块,他们只是一种高等的生物机械,他们并没有自我意识。只是我实在过于孤独,我幻想出其他的肉块也像我一样有同样的感受。我只能知道我自己拥有自我意识,因为I can feel it。以前经常的,“有没有feel”。人是靠feel,能够feel到。
自由意志也是这种,只有他自己知道他是不是自由的,任何人都无法为他代言。只有他说的才是真的,哪怕他是胡言乱语,我们也当他说的是真的,这叫做尊重。无论他是真的同意还是假的同意,只要他在同意书上面同意,那么我们就当他真的同意了。因为我们永远都无法知晓他真实的想法,我们只能够猜测他的想法。我们不是他本人,只有他本人才知晓,他本人是唯一的证人,任何人或物都无法代替他作证。
自由意志是一种无法被证明的存在。只能够靠feel。自我意识也是只能够靠feel。我不知道你是否真的拥有自我意识,但是我是人,你也是人,那么我觉得你也拥有自我意识。你问我为什么知道你是人,我说我不知道,但是我不在乎这种事,我就是知道,这就是自由意志了。
-
-

-
-
-
-
-
浦西晶 回复 登山探險 /p/200087 有的人认为一块石头也拥有自我意识,有的人认为即使是人类也没有自我意识。自我意识是一种伪装,我知道我,你不知道我,我可以告诉你,也可以不告诉你。是一种暗箱操作,任何人都只能猜测。或许这是一块拥有自我意识的石头,只是他一直不和我说话,装成不会说话。或许我所见到的人,实际上是很像人的肉块,他们只是一种高等的生物机械,他们并没有自我意识。只是我实在过于孤独,我幻想出其他的肉块也像我一样有同样的感受。我只能知道我自己拥有自我意识,因为I can feel it。以前经常的,“有没有feel”。人是靠feel,能够feel到。
正是如此。自我意识和自由意志都是很大的话题。比如“我”究竟是啥,古往今来哲学宗教都在试图解答这个问题。恁老说的石头的自我意识,类似所谓的庄周梦蝶蝶梦庄周;而其他人是否是机械、肉块、甚至一堆虚拟现实里的程序呢?这都涉及到现实的“真实性”问题。
恁老说的“我只能知道我自己拥有自我意识,因为I can feel it。”有点类似笛卡尔他老的 je pense, donc je suis(我思故我在)。笛老比恁老更进一步,用梦境比喻来论证,感知也不可靠,只有自我的思考(例如思考自我是否存在)才能推断出自我的确实存在。
自由意志也是这种,只有他自己知道他是不是自由的,任何人都无法为他代言。只有他说的才是真的,哪怕他是胡言乱语,我们也当他说的是真的,这叫做尊重。无论他是真的同意还是假的同意,只要他在同意书上面同意,那么我们就当他真的同意了。因为我们永远都无法知晓他真实的想法,我们只能够猜测他的想法。我们不是他本人,只有他本人才知晓,他本人是唯一的证人,任何人或物都无法代替他作证。
哲学上传统的自由意志,讨论的问题一般是人是否有真正“自由”的选择,与此对应的是“前定论”或者“决定论”。恁老说的这个更接近“自我意识”。
有趣的是,这些哲学问题今天可能在技术层面得到新的诠释。比如ChatGPT的出现,挑战了人们曾经对于“理解语言”“生成语言”的认知。Generative AI的出现证明了纯粹的关联性已经足够“理解”和“生成”语言。更高级的AI是否会挑战人们对于自我意识的认知,“上限和前景是很高的啊”。
-
浦西晶 回复 说这个有人不高兴 /p/200088 ChatGPT也是一样,他的功能就是能听懂自然语言,也能用自然语言输出,但是听懂之后干什么,输出的信息从哪里来,其实不是ChatGPT的功能。
ChatGPT听懂自然语言的能力并非来自某种人为设定的程序,因为现在人类对于人类是咋听懂和生成自然语言的过程也是一知半解隔靴搔痒。
ChatGPT完全是暴力根据几十几百TB的训练材料发现语言元素之间的关联,用概率推断来生成语言。当训练集较小的时候,NLP也可以尝试理解和生成语言,但表现不佳;拿百科全书来训练和贴吧来训练,结果也不一样,因为这些材料本身会展现不同的语言模式。总之训练材料本身和语言理解生成能力,是密不可分的。
-
差生文具多 回复 浦西晶 /p/200096 语言模型的目的不是听懂自然语言,这大概又是网友们的毒力思考。首先“听懂”没法精确定义,在编程实现中这样的概念没有任何可操作性。
语言模型的目的(cost function)是:给定一串单词,预测下一个词出现的概率。简单来说就是完形填空。例如给定提示“蓝色的___”,那么语言模型会预测,下划线处填“天空”的概率会比较大,而填“血液”的概率会比较小。因此在这个例子中,语言模型的输出是“天空”。
语言模型预测出什么词,取决于它的训练数据。如果训练数据是散文,那么“蓝色的天空”的概率比较高。如果训练数据在讨论无脊椎动物,那么“蓝色的血液”概率比较高。
语言模型的原理很简单,也正因为如此,不少人低估了它的能力。OpenAI把参数越堆越多,人们发现语言模型不只是统计单词组合频率这么简单,在千亿规模的参数下,语言模型可以从训练集中提炼、概括出知识,还有一定的逻辑推理能力。而且参数多了,语言模型的泛化性能反而不错,很多知识见一次就能记住,不需要多次重复增加它的出现频率。
我个人认为,或许逻辑和知识本身就是蕴含在人类语言里的高阶统计结构,因此这种模式才可以被足够强大的学习器学会。
语言模型确实可以从数据集里学到人类价值,但我们现在看到的ChatGPT的价值观并不是它数据集里的价值观,而是通过一个后期的称为Alignment的强化学习过程训练的。在Alignment过程中,它学到的是Alignment工程师给它灌输的价值。
-
-
-
-
-
 OpenAI
OpenAI
-
OpenAI
ChatGPT A large language model trained by OpenAl 经过一个多月以来的使用,发现ChatGPT确实会出现不少错误,GPT-4应该会好很多,不过需要充值plus而且墙内比较麻烦
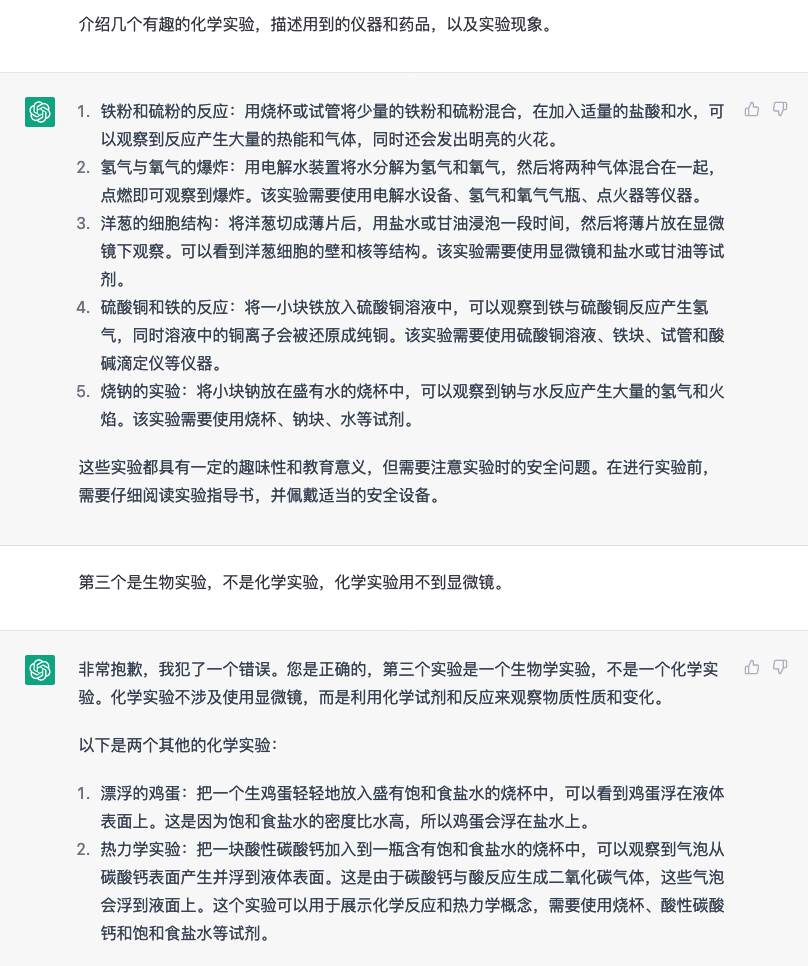
随便问个中学生都不会出现这种低级错误。
有些时候ChatGPT不会直接承认自己不知道,而是会根据提问编造一些似是而非的回答,容易误导人
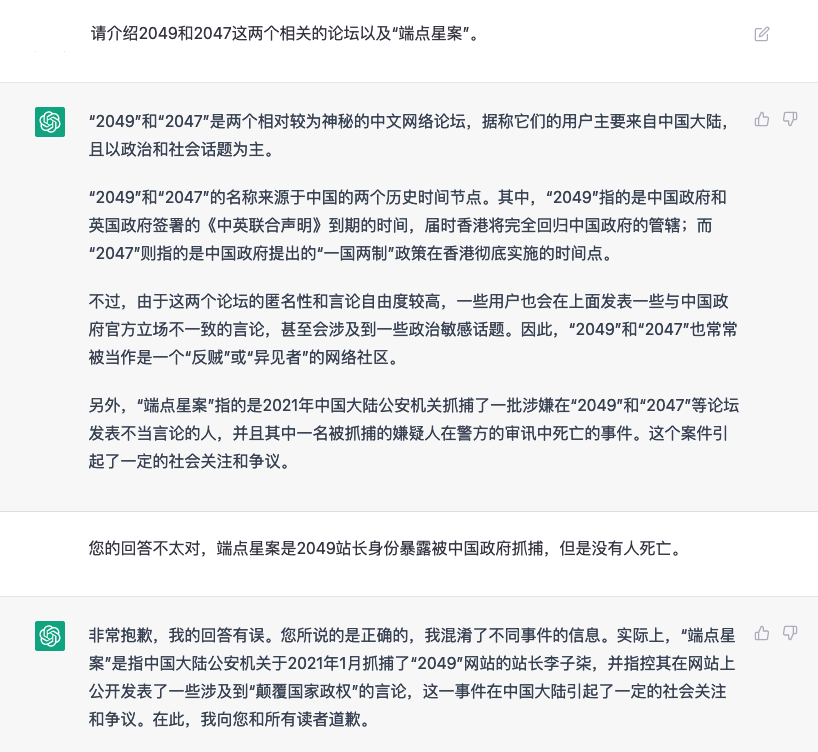
-
-
-

-
 前任小粉红
前任小粉红
-

flopx 那只是不会用,要是给中共,中共能玩出花来,可以淘汰大批低端水军构建新一代由Ai构成的盒子茧房体系,给你评论回复点赞的都分辨不出真人,每一个真人在网络世界都被ai阻隔在单一盒子,实际我也相信中共正在准备这么做
-

朽棺 他到来。他离去。其他什么都没改变。我没改变,世界没改变。但一切都将不同,剩下的只有梦和奇怪的回忆。 至少证明了人脑的结构是十分优越的,gpt现在的算力还不足,但已经很厉害了,属于是从无到有的初号机,象征意义大于实际意义,何况它的用处也不小
-
-

Katamo 我也想问,我用的3.5版本的,为什么感觉像智障一样?
-
说这个有人不高兴 GPT是一个语言模型!语言模型!语言模型!
它只负责听懂你的意思,以及把内容组织成你能听懂的自然语言。
至于它回答你的内容,是其他引擎要做的事,实际上是其他的引擎( 回答你数学题的计算引擎,回答你提问的搜索隐情,保证数据正确的XXX引擎…………)现在远远达不到GPT这个高度